
手書きのノートが数冊あって、あれこれ調査した末、このサービスを使えばなんとかこれをテキスト化する作業が進められそうな有望なツールが見つかった(既報)。作業完了まではまだ遠いが、これまでの経過を記録しておきたい。
1.背景
子どもが交通事故に遭い、瀕死の重体から蘇生し、回復していった。その間、できるだけ詳細な記録を残しておこうと、日々の出来事をノートに書き溜めた。それがノート5冊となって手元に残ったが、手書きのままでは可読性が低く、検索もままならないので、いずれテキスト化したいと考えていた。最初の二週間分(約15万字ほど)までは、眼で読み、キーボードを叩くという普通の人力での文字起こし(テキスト化)をしてきたのだが、根が続かず、中断したまま何年も放置していた。再開しなければという焦りが閾値を超え、なんか楽な(横着できる)手はないかと探り始めた。
2.OCRの調査と試用
iPad+ApplePencilのスクリブル機能に衝撃を受けてはや三年以上になるが、この間のAIの進化は目覚ましく、これは手書き文字OCRの性能の向上にも寄与しているはずだ、と見当をつけ、数種類のサービスやプログラムを試してみた(参照)。そのなかでGoogle Cloud Vision AI OCRサービス(以下、GC-AI-OCRと略記)の成績が傑出しており、これなら文字起こしの作業負荷、とりわけOCR処理後の誤認識文字の校訂作業の負荷がかなり軽減できると実感できた。
3.OCR処理の前処理
手書きの原本は、A4版6mm横罫のノートで、青のボールペン(芯の太さは0.4~0.5mm)で一行平均約50文字がびっしり書き込まれている(添付d)。悪筆のうえに走り書きにちかく、自己流の崩しや、略字も多く、漢字、かな、カナ、アルファベット、数字が混在している。書き損じを取り消し線で抹消した箇所や、後から言葉を挿入したり文字を補ったりで、行が乱れている箇所もそこかしこにある。
GC-AI-OCRへの入力はpngフォーマットの画像データなので、スキャナ(注1)で、ノートの各ページを、カラーはモノクロ、解像度は600x600dpiの設定でスキャン処理し、png画像を作成した。ノートの保存状態が悪くてカールがあり画像が部分的に掠れたり歪んだり、行の端まで書き込まれた文字がスキャン枠から外れてしまったりで、画像の品質はページ間でだいぶばらつきがでた。png画像の平均サイズは約1.4MB、220ページ分で、計314MBとなった。
4.Google Cloud AI OCR
4.1.サービスの概要
Google CloudサービスはWebで提供される膨大で多岐にわたるサービス群で、とても簡単に要約できるようなものではないが、私が利用したのは、その中のVision AIという、「視覚データをAIで分析解釈し、意味のある情報を引き出す」機能で、API(注2)経由で画像内の文字認識を行うものだ。
このAPIはGoogle Cloud Shell(注3)からPythonプラグラム経由で呼び出せるようになっている(添付a)。
4.2 ユーザ登録、認証等
Google Cloudeを利用するには、Googleアカウント(注4)をGoogleCloudユーザとして登録する必要がある。登録済みのユーザには仮想の開発・実行環境が提供され、CloudShellでアクセスできるようになる。使いたい機能に応じてプロジェクトを定義し、課金用の情報(クレジットカード番号など)を設定し(無料サービスの場合でもこの設定は必須のようだ(注5))、ライブラリ(機能をサポートするサブルーチン群)のセットを配置する。プロジェクトが承認されると認証用のパスキーが付与されるので、必要に応じて提示する。
(ユーザ登録やプロジェクト定義の手順は、逐一の記録はしていなかったので、うろ覚えなのだが、ChatGPTに導かれるままに作業を進めていくうちにできていたというのが真相に近い)。
4.3 Pythonプログラム
GC-AI−OCRのAPIを呼び出すPythonプログラムは、まるまるChatGPTに生成してもらった(添付e)。実行の都度、入力ファイルのロケーションを修正するだけで、正常に動作した。
4.4 プログラムの実行準備
Pythonプログラム(ソース)と、入力用のpngファイルを、CloudShellから開発実行環境にアップロードする(添付a)。
4.5 実行
CloudShellでPythonプログラムを実行する。pngファイルがOCRエンジンで処理され、結果のテキストファイルが出力される(添付a)。
CloudShellでOCR実行結果のテキストファイルを自分のPCへダウンロードする。テキストファイルのサイズは合計1.6MBであった(添付a)。
5.OCRの後処理
GC-AI−OCRの認識率は非常に高く、私のケースでは90%を優に超えているが、それでも誤認識を少なからず含んでおり、校訂作業は必須である。この校訂作業が一番労力がかかり、ちまちまと地道に進めていくほかはない。怠け者には難儀な日課だが、ようやく先がみえてきたところだ。
添付資料
a. OCR処理のフロー
手書き文字OCR処理システムの全体像は、図1.のようになる。
図1.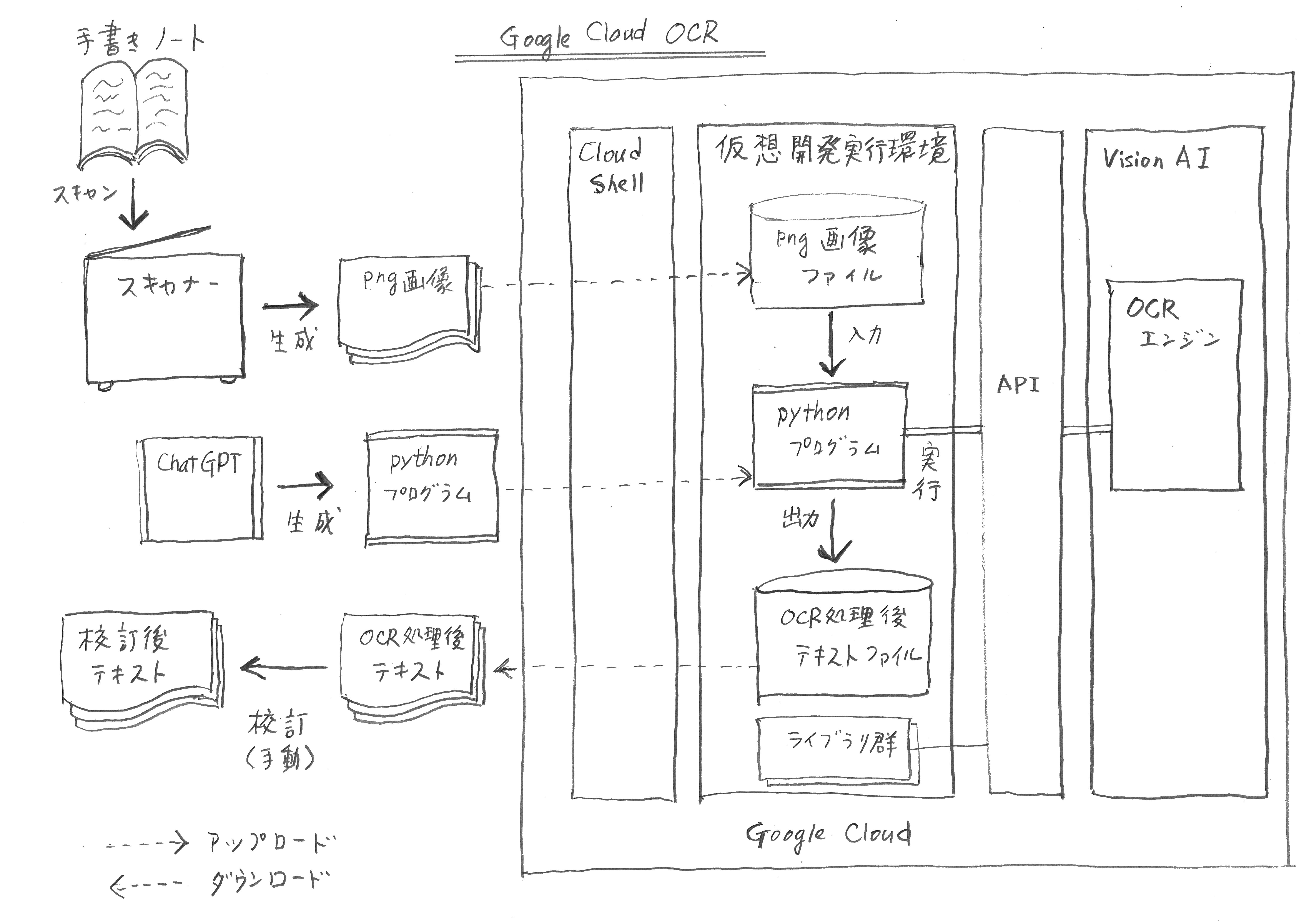
この図がこの記事の中で手書きのまま置かれているのは冗談のようだが、GhatGPTやGeminiをはじめとするAIにこの手書きの図を与えて、清書してくれと依頼してはみたのだ。しかし、使い物になるまともな回答は皆無だった。ちょっと意外な盲点かも知れない。
b. OCRの認識率
OCRの文字認識率は([正しく読み取った文字数] / [全体の文字数])*100だと単純に考えていたが、学術的にはレーベンシュタイン距離(編集距離)という尺度で測定するものだそうだ。よく知らないのでので、解説は付けられないが、OCR処理結果と校正後の正テキストを与えれば、GC-AI-OCRが算出してくれる(そのためのPythonプログラムはChatGPTが生成してくれた)。何か所かサンプリングして認識率を測定した結果が下の表である。
# 認識率 正テキスト文字数 0CR処理文字数
#1 91.85% 6693 6615
#2 95.66% 6578 6589
#3 93.44% 6275 6222
#4 77.83% 6084 5884
#4は、紙のカールやインクの掠れがなどの悪条件が重なって画像の品質が非常に悪く、文字として認識されない箇所が多数あって、極端に認識率が悪い。
c. 認識率に影響を及ぼすイメージデータの品質
今回は画像データとしてモノクロのpngデータを使用した。しかし、事後に確認したのだが、実は24bitフルカラーのデータのほうが認識率は高くなる。Googleもそちらを推奨している。ぼやけや掠れを補正するための情報が増えるのであろう。ただし、今回のような元データの条件(6mm罫線に細字用ボールペンの文字)では、解像度は600dpi程度がよくて、それより高い解像度だとデータサイズの増加に見合う認識率の改善は見込めないようだ。
d. 実際の手書きメモとOCR処理結果(校訂前)と校訂後テキストのサンプル
事故から18日経ち、ようやく運動機能や記憶が回復しかかった頃の記録の一部を抜粋した。
手書き文字

OCR処理結果テキスト

校訂後テキスト

e. Pythonコード
OCR処理のためのPythonコード(ChatGPTが生成)

1.スキャナ 使用したのは、Brother MFC-J998DNというプリンタ・スキャナ複合機である。スキャンはノートを開いてスキャナにかぶせ、位置合わせして上からカバーで押さえ付ける方式である。iPhoneのカメラに書類スキャンの機能があるので、それを使ってもよかったのだが、出力形式がPDFしかなく、GC-AI-OCRがもとめるpngにするには変換操作が必要になるので、Macに直接pngファイルを取り込める複合機のほうを採用した。
スキャナの性能の問題ではないが、ノートの保存状態が悪くてページがカールしているため、部分的にガラス面から浮いて画像が歪んだりぼやけたりする、あるいは、カバーを閉じるときに位置合わせがズレてページがスキャン枠からはみ出したりする。ボールペンのインクが薄くて掠れが強いページもある。画像の品質が一定しないために、度々スキャンのやり直しを余儀なくされた。
2.API Application Programing Interfaceの略。アプリケーション・プログラムから外部の機能を呼び出す仕組み。ここではPythonプログラムがGC-AI-OCRを呼び出している。
3.Shell コマンドを通じてシステムの機能を利用するためのインターフェース。GoogleCloudも、Shellを備えており、仮想開発実行環境へのインターフェースとなっている(だからブラウザで稼働する)。
4.Googleアカウント Googleのサービスを記名で利用するためのアカウント。gmailアカウントはその代表であり、gmailアカウントをすでに持っていれば、そのまま使えばよい。もちろん、GoogleCloudのサービスを使うための追加の設定は必要になるが。
5. 今回のサービス利用は無料だった。処理量がさらに増え、画像データのサイズが100GBを超すと課金されるようだ。